Profiling Tools
Introduction
This tutorial will guide you how to run intel profiling tools in AMD processors, we explore also the type of code we can profile.
Advisor
Project setup
First of all, we prepare an executable to run the tests. You can use any code to run these examples. Here we use for the nqueens example provided by advisor installation. We copy it from advisor installation directory:
cp /dcsrsoft/spack/external/intel/2021.2/advisor/2021.2.0/samples/en/C++/nqueens_Advisor.tgz .
Then, extract the contents and compile the serial version:
make 1_nqueens_serial
Creating a project
We create a project using advisor gui:
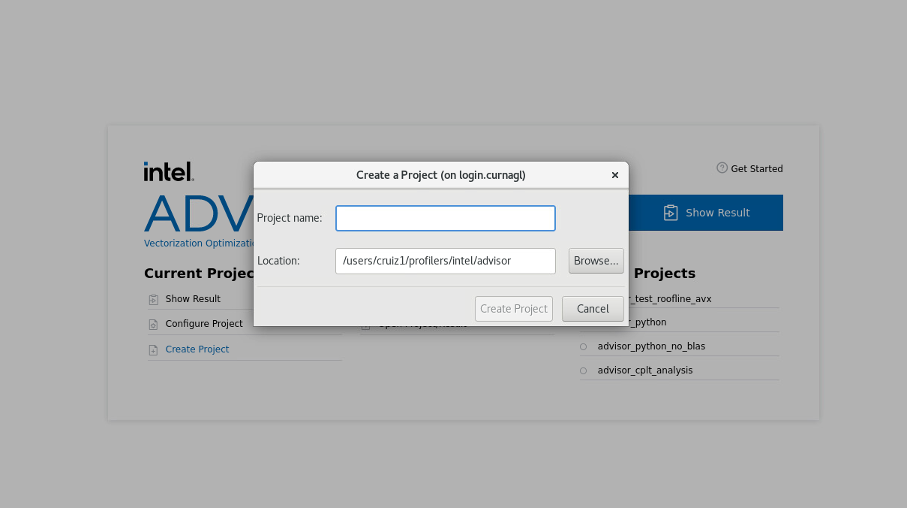
We configure the path of our nqueens executable (or the executable you want to profile), and we click on OK.
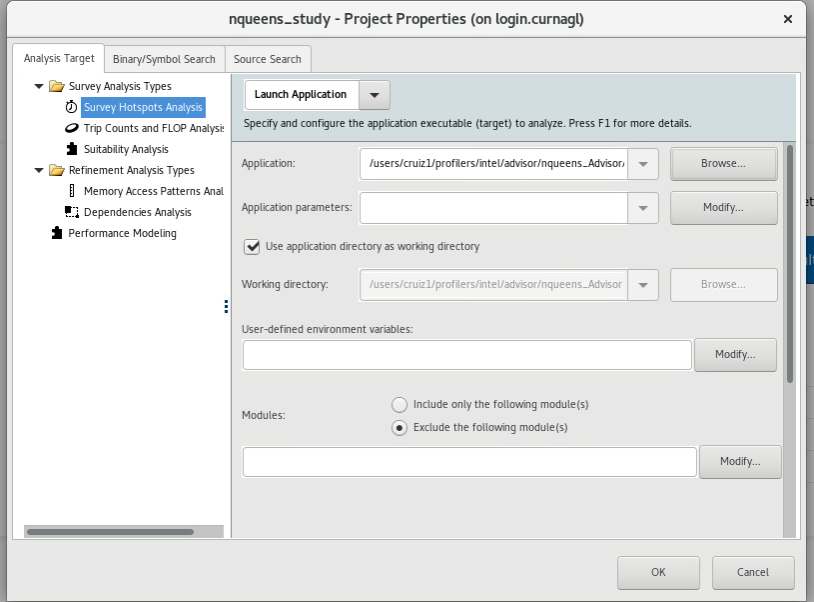
Several analysis are proposed :

We start with Vectorization and Code insights which will give us information about the parallelization opportunities in the code. It identifies loops that will benefit most from vector parallelism, discover performance issues, etc. The summary window will give us more details.
Using SLURM
To use Advisor in the cluster, it is better to use the command line. The GUI can provide the commands we should run. Let’s run the survey, to see the command to run, click on the following button
This will show the exact command to use:
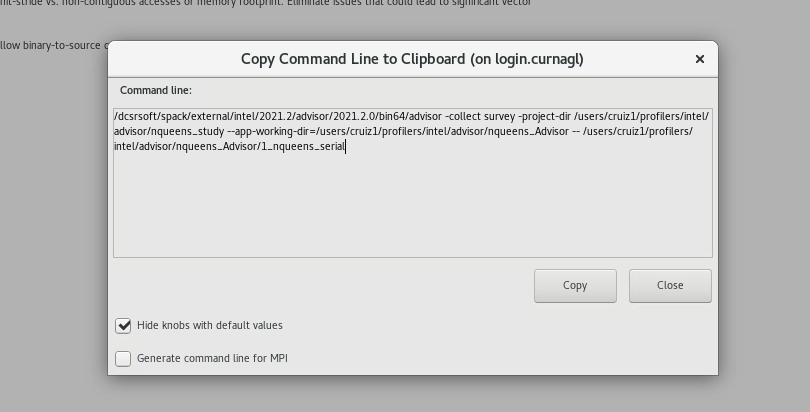
We can copy that line in our slurm job:
#!/bin/sh
#SBATCH --job-name test-prof
#SBATCH --error advisor-%j.error
#SBATCH --output advisor-%j.out
#SBATCH -N 1
#SBATCH --cpus-per-task 1
#SBATCH --partition cpu
#SBATCH --time 1:00:00
dcsrsoft/spack/external/intel/2021.2/advisor/2021.2.0/bin64/advisor -collect survey -project-dir /users/cruiz1/profilers/intel/advisor/nqueens_study --app-working-dir=/users/cruiz1/profilers/intel/advisor/nqueens_Advisor -- /use\
rs/cruiz1/profilers/intel/advisor/nqueens_Advisor/1_nqueens_serial
we launch the job:
sbatch slurm_advisor.sh
check for errors in Slurm output files.
Checking results
If we close and reopen the project, we see that we have some results:
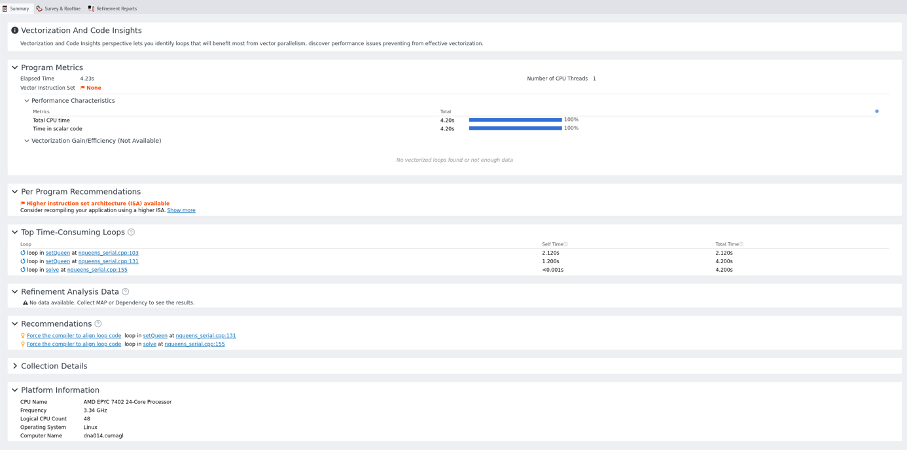
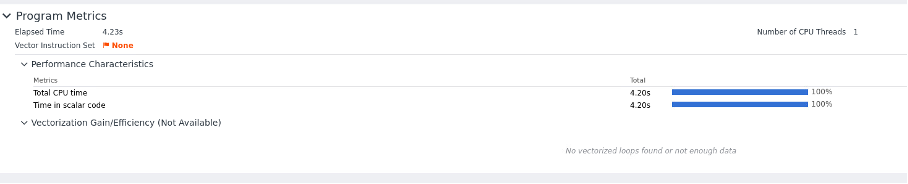
We have recommendations for using other instruction sets because no vector instruction set was detected.

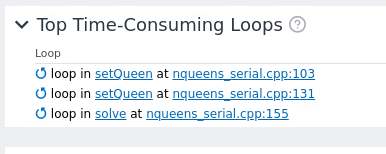
We see the most time consuming loops:
It detects correctly the AMD CPU
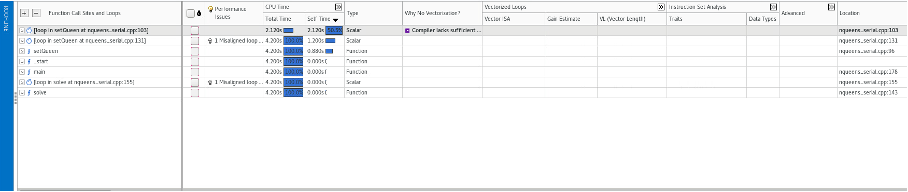
In the survey window we can observer the time consuming parts of the code. Each line on the table represent either a function call or a loop. Several useful information is presented by line such as: vector instructions used, length of the vector instruction and type of data.
 On the window above, we should see recommendation about the vector instructions to use. This is missing probably due to the fact that we are using an AMD processors. Compilation of code using Intel compiler did not help.
On the window above, we should see recommendation about the vector instructions to use. This is missing probably due to the fact that we are using an AMD processors. Compilation of code using Intel compiler did not help.
The lower half of the screen shows the following tabs:
- source code (available if compiled with -g)
- top down shows the call tree
- code analysis shows the most time consuming loop as well as a profile of the application in terms of resources (CPU, memory)
On the top down tab, we can see where the call is taking place:

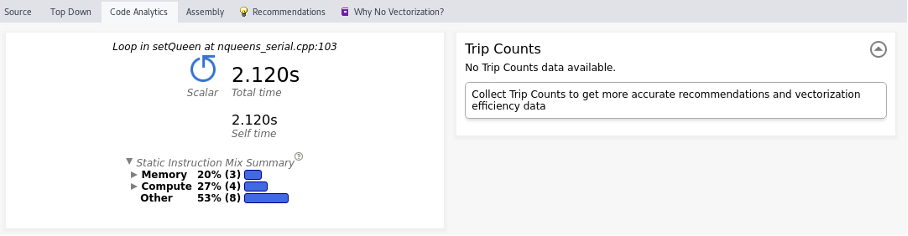
Below a screenshot of the code analysis window.
Collecting trip counts
We choose characterization analysis. To improve the analysis we should choose a loop, this can be done on the survey window:
 And then launch the characterizitation, again we ask for the cmd line :
And then launch the characterizitation, again we ask for the cmd line :
The generated command will contain the additional options:
tripcounts -flop -stacks -mark-up-list-2
We can see the different trip counts for each loop:
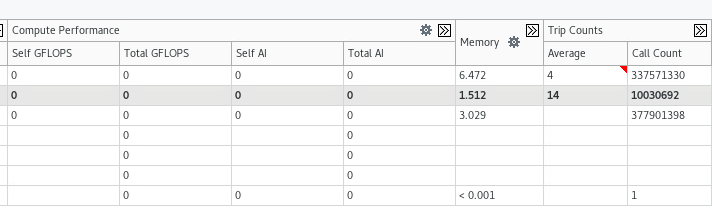
We can now repeat the process for memory access analysis. After running the analysis, we have new information:
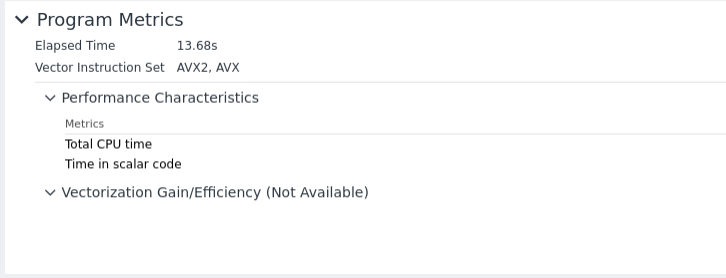
 If we compile the code with more performant instruction set, this is detected in the summary window:
If we compile the code with more performant instruction set, this is detected in the summary window:
and the call stack window:
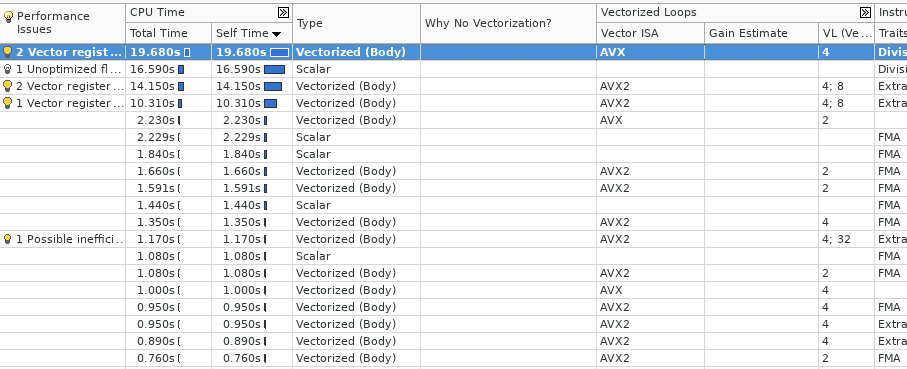
This screenshoot was obtained profiling HPL Benchmark.
MPI profiling
The command proposed by the GUI is not the appropriate, we should use the following command:
srun advisor --collect survey --trace-mpi -project-dir /users/cruiz1/profilers/intel/advisor/analysis_mpi_trace-2 --app-working-dir=/users/cruiz1/profilers/intel/advisor/mpi_sample -- /users/cruiz1/profilers/intel/advisor/mpi_sample/mpi_sample_serialThe default behavior generates a profile database per rank which is not ideal to understand the interactions between MPI ranks. We can use the option --mpi-trace but unfortunately it does not seem to give more additional information as it only works if we use the same host.
One possible approach is to only profile one processes using SLURM multiprogram option:
srun --multi-prog task.conf
the task.conf would look like:
0 /dcsrsoft/spack/external/intel/2021.2/advisor/2021.2.0/bin64/advisor -collect survey -project-dir $PROJECT_DIR -- $PATH_BINARY/xhpl
1-3 ./xhplIn this example, we profile the rank 0.
Python application
It is possible to profile python applications by adding '--profile-python' option. For example to profile a tensorflow code:
advisor -collect survey --profile-python -project-dir /users/cruiz1/profilers/intel/advisor/tensor_flow_study -- python /users/cruiz1/python/run_test.pyWe have the following summary:
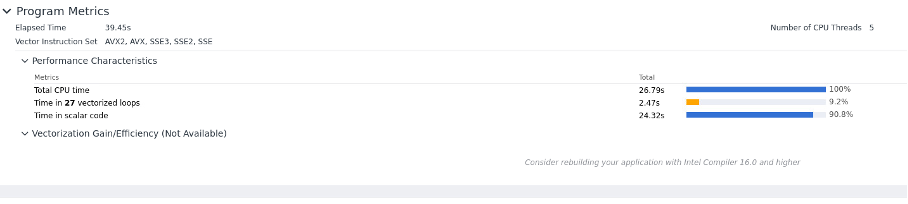
We can see that the code uses vector instruction (In this example the CPU version of Tensorflow was used).
The complete call tree shows:
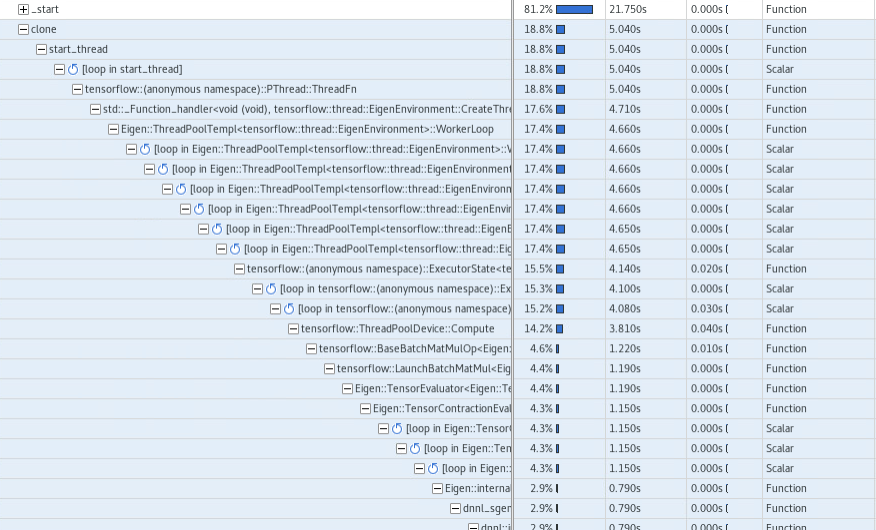
We can explore the main script and how CPU time is distributed:

Unfortunately, this is not automatic, we should filter it using the source file filter, example:

Intel VTune
Limitations
Limited number of analysis
Unfortunately, for most of the analysis:
- hpc-performance
- memory-acesss
- performance snapshot
- uarch-exploration
- io
we obtained the following error message:
vtune: Error: This analysis type is not applicable to the system because VTune Profiler cannot recognize the processor.
If this is a new Intel processor, please check for an updated version of VTune Profiler. If this is an unreleased Intel processor
for io analysis we have the following error:
vtune: Error: Cannot enable event-based sampling collection: Architectural Performance Monitoring version is 0. Make sure the vPMU feature is enabled in your hypervisor.
Maximum number of threads
The tool detect a maximum number of 16 threads
Launching analysis in SLURM
We can still do some analysis like 'hotspots analysis'.
#!/bin/sh
#SBATCH --job-name test-vtune
#SBATCH --error vtune-%j.error
#SBATCH --output vtune-%j.out
#SBATCH -N 1
#SBATCH --cpus-per-task 8
#SBATCH --partition cpu
#SBATCH --time 1:00:00
export OMP_NUM_THREADS=8
source /dcsrsoft/spack/external/intel/2021.2/vtune/2021.2.0/amplxe-vars.sh
vtune -collect hotspots ./matrixHotspot analysis
The summary window looks like:
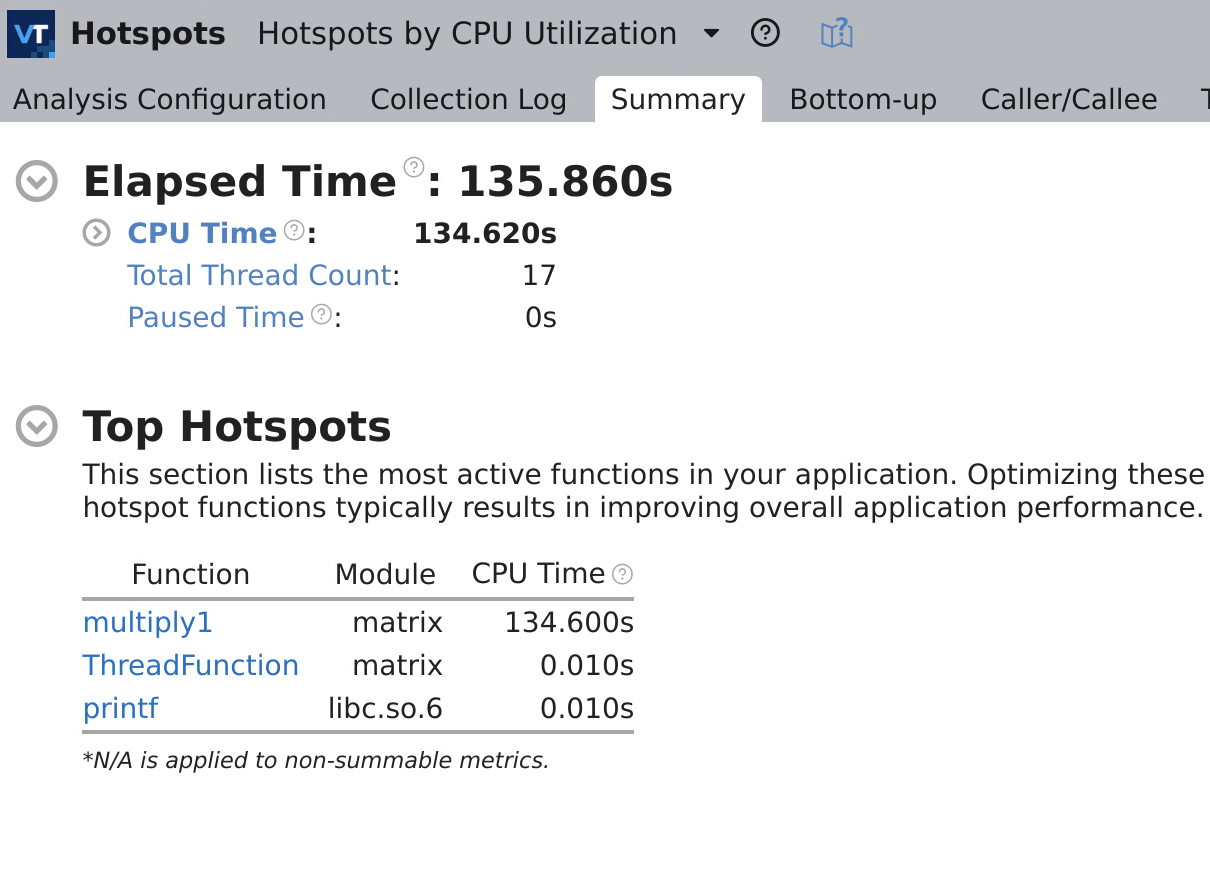
On the bottom section we can see a profile per thread, where we can see how well balanced is the application:

Memory consumption analysis

Threading analysis:
This graph shows the distribution of active threads for a given computation. We observe for this example 8 and 16 that run simultaneously.

It shows more details:

Application using external libraries:
we can see how the CPU time was used by external libraries. This is accomplish by doing choosing process/module view.
